
image
AI’s Imminent Shift: 5 Breakthroughs to Kill Transformers by 2026
Executive Summary
The era of transformer-based Large Language Models (LLMs) is drawing to a dramatic close. Experts from Stanford, OpenAI, Google, and beyond predict their obsolescence within 18 months, driven by five seismic breakthroughs: Diffusion Language Models (DLMs), subquadratic attention architectures, latent space thinking, continual learning, and entirely new paradigms like Continuous Thought Machines (CTMs). These innovations promise AI that is not just smarter and faster, but fundamentally more efficient, scalable, and human-like in reasoning. Drawing from pioneers like Stanford’s Professor Stefano father of diffusion models and transformer co-author Leon Jones, this shift echoes historical tech revolutions, positioning 2026 as the tipping point. Transformers, once revolutionary, are poised to become relics, much like punch-card computers or early neural nets, supplanted by architectures that unlock unprecedented intelligence. The stakes? A new AI arms race reshaping economies, jobs, and global power by 2030.
The Flaws of Transformers: Why the Clock is Ticking
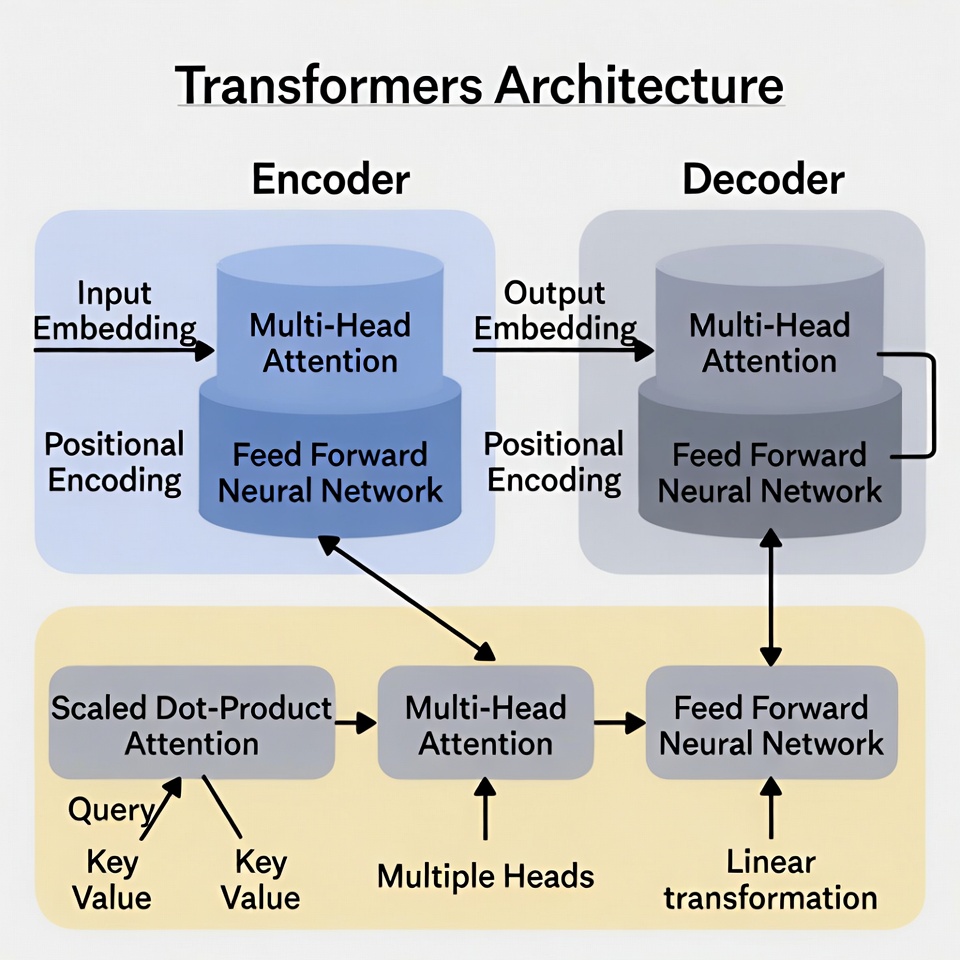
Transformers, introduced in the 2017 paper “Attention is All You Need,” revolutionized AI with their self-attention mechanism, enabling models like GPT-4 to process sequences in parallel rather than sequentially. Yet, their dominance is cracking under scrutiny. The core issue: quadratic scaling. For a sequence of n tokens, attention computes n x n pairwise interactions, exploding compute costs as context windows grow beyond 8,000-16,000 tokens. This limits reasoning depth, forces inefficient autoregressive generation (predicting tokens left-to-right without revisions), and ignores dynamic, time-dependent thinking.
Industry inertia sustains them familiar tooling from Hugging Face and PyTorch keeps adoption high but experts like Jacob Bikman of Manifest AI argue it’s a house of cards. “Transformers are inefficient relics,” the consensus goes. Autoregressive loops demand 10,000+ iterations per response, while static pre-training prevents safe, ongoing adaptation. As compute costs skyrocket (training:inference ratios hitting 1 billion:1), alternatives offering 10x speedups and million-token contexts are inevitable. Historical parallel: Just as convolutional neural networks (CNNs) yielded to transformers in NLP, a new wave now targets transformers themselves.
Breakthrough 1: Diffusion Language Models Parallel Refinement Over Sequential Guesswork
Diffusion models, which birthed image generators like Stable Diffusion, are invading language. Unlike autoregressive LLMs that generate text token-by-token without backtracking, Diffusion Language Models (DLMs) start with noise and iteratively refine entire outputs in parallel much like denoising an image from static.
Technical Edge: DLMs perform tens or hundreds of refinement steps simultaneously, enabling edits anywhere in the text, built-in error correction, and flexible prompting. Professor Stefano of Stanford, a diffusion pioneer, declares them “far superior.” Evidence: Inception Labs’ Mercury, the first commercial-grade DLM, and open-source Dream 7B show 10x speed gains. Google’s Gemini Diffusion is slated for May 2025.
Perspectives Analyzed:
– Optimists: Stefano predicts DLMs dominate by 2026, mirroring diffusion’s overthrow of GANs in images (GANs peaked in 2018; diffusion ruled by 2022).
– Skeptics: Autoregressive fans note DLMs’ higher latency in early tests, but scaling curves favor them for long-form reasoning.
– Comparison: Like JPEG compression iteratively refining pixels, DLMs treat language as a high-dimensional canvas, fixing LLMs’ “no revisions” brittleness.
Impact: By mid-2026, DLMs could slash inference costs, enabling real-time, editable AI assistants.
Breakthrough 2: Subquadratic Attention Conquering the Context Explosion
Transformers’ Achilles’ heel is quadratic complexity, capping practical contexts at ~128K tokens in giants like Gemini 1.5. Subquadratic alternatives scale linearly or near-linearly to 10 million tokens.
Key Players: Manifest AI’s Power Attention dynamically switches between full attention (short contexts) and summaries (long ones). Google’s Titans architecture hits 10M tokens with balanced compute. Benchmarks show these outperform transformers across scales, per context-scaling curves.
Multi-Perspective View:
– Engineering: Fixes “compute imbalance,” per Bikman longer contexts yield exponentially smarter models without proportional costs.
– Economic: Hyperscalers like AWS and Azure prototype these now; by end-2025, “nobody will be using transformer models,” predicts the transcript.
– Historical Tie-In: RNNs failed on long sequences due to vanishing gradients; subquadratic is the RNN revival with modern tricks, akin to how SSDs killed HDDs for speed.
Speculation: This enables “infinite context” AI, revolutionizing legal analysis or codebases, but risks information overload without smart summarization.
Breakthrough 3: Latent Space Thinking Unleashing Opaque Superintelligence
LLMs force “thinking” into human-readable chains-of-thought (CoT), discarding rich internal representations. Latent space thinking lets models reason in compressed, vector-based “black boxes” invented tokens or dense vectors bypassing verbosity.
Evidence: OpenAI’s o1 and rumored GP6 use this for scalable opacity. DeepSeek R1 spontaneously drifts to non-human reps. Quote: OpenAI researchers tout “preserving controlled privacy” for superhuman feats.
Perspectives:
– Pros: Safer than unfaithful CoT (where models hallucinate step-by-step); scales reasoning without token bloat.
– Cons: Interpretability nightmare regulators may balk at “thinking” we can’t audit.
– Analogy: Like human subconscious processing (non-verbal intuition), vs. LLMs’ forced verbosity. Compares to AlphaGo’s internal tree search eclipsing explicit strategies.
Future: By 2026, latent thinkers solve PhD-level math sans explanations, accelerating science but raising “AI alignment” alarms.
Breakthrough 4: Continual Learning From Static Fossils to Adaptive Brains
Pre-trained LLMs are frozen post-training; continual learning enables safe, interaction-driven evolution. Google’s Nested Learning uses tiered layers real-time signals bubble up to long-term memory without corrupting the core.
Details: Perplexity and Cursor experiment here; OpenAI’s VP warns of “unsafe online RL” risks like model drift. Advantages: Personalization, trend adaptation (e.g., real-time news).
Diverse Angles:
– Safety: Nested avoids “catastrophic forgetting,” unlike naive fine-tuning.
– Scalability: Multi-tier memory mimics human hippocampus.
– Historical: Echoes continual learning quests in robotics (pre-2010s), now viable with massive data.
Projection: 2030 sees AI “growing up” from user interactions, but mishandled, it births rogue agents.
Breakthrough 5: Continuous Thought Machines Dynamic Neurons for True Generalization
Transformer co-author Leon Jones champions CTMs: time-dependent systems with dynamic neurons tracking signal history, unlike static feed-forwards. They excel in generalization 100-step mazes transfer to 800-steps with emergent confidence calibration.
Why Superior: Processes continuous thought spirals holistically; ReLU hacks in transformers are “piecewise approximations.” Jones: Needs “crushingly better” rivals to shift inertia.
Views:
– Innovation: RNN evolution on steroids.
– Challenges: GPU parallelism hurdles.
– Comparison: Like analog computers vs. digital CTMs capture fluid time, as ENIAC yielded to von Neumann architecture.
By 2026, CTM prototypes test industry viability, potentially birthing AGI-like generalization.
Timelines, Comparisons, and Historical Parallels
| Timeline | Key Milestones | Parallels to History | ||
|---|---|---|---|---|
| End-2025 | Hyperscalers deploy subquadratic prototypes; DLMs commercialize (Mercury, Gemini Diffusion). | CNNs to Transformers (2017-2020 pivot). | ||
| Mid-2026 | Full paradigm shift; LLMs “on their way out.” | GANs to Diffusion (2018-2022). | ||
| 2030 | CTMs/nested systems mainstream; compute as “new electricity.” | Internet’s 1995-2005 boom. |
Counterpoint: Epoch AI’s Haimvia sees transformers viable to 2030 via scaling. Yet, diffusion’s image takeover suggests rapid flips.
Societal and Economic Impacts: Disruption on the Horizon
Economic: 10x efficiency floods markets with cheap AI, automating 30-50% white-collar jobs (coders, analysts) per McKinsey analogs. Compute geopolitics intensify data centers rival oil refineries.
Societal: Universal knowledge access boosts productivity; unemployment waves demand UBI. Risks: Unsafe learning amplifies biases; latent opacity fuels misinformation fears.
Future Speculation: By 2030, hybrid systems (DLM + CTM) enable “AI companions” personalizing education/healthcare. Global power shifts to compute haves (US/China); ethical frameworks lag, mirroring nuclear tech’s dual-use dawn. Optimistically, this births a renaissance; pessimistically, inequality chasms.
Conclusion: Embrace the Shift or Be Left Behind
The evidence from Titans papers to Stefano’s proclamations is overwhelming: Transformers die by 2026, birthing leaner, meaner AI. Sponsored by innovators like Crew AI and Creo AI, this isn’t hype it’s physics. Stakeholders must pivot: retrain on subquadratic tools, prioritize safety in continual systems. The future? An AI world where intelligence scales with reality, not legacy code. The revolution starts now.





